
You need to have high-availability of a resource – say, an IP. To do this on Linux you have two main choices: the linux HA suite (pacemaker/corosync) or keepalived. Pacemaker/corosync are more complex, but that’s because they can do more things – fencing, STONITH, resource affinities, counter affinities, etc.. Meanwhile, keepalived really only manages one type of resource, the IP, and it does so via what is effectively VRRP with shell scripts. Keepalived is thus massively simpler to configure and operate, but with the tradeoff that you can’t do nearly as much with it.
Note: Keepalived also works with LVS to be a kind of end-to-end L3/L4 load-balancing solution. VRRP with shell scripts remains an integral critique and fundamental weakness of it though.
What is VRRP?
Virtual router redundancy protocol. VRRP arose out of a basic need – I want to have my routers and thus network possess redundancy (you know, for reasons), but only one can have a gateway at any given time. So you plug them into each other, have them heartbeat, set one as a master and call it a day.
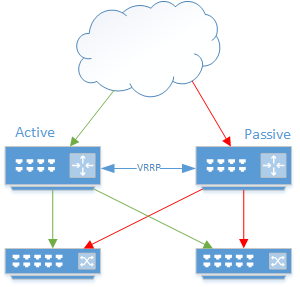
So what’s the problem?
This works absolutely beautifully for two devices that are directly attached and share links (we also have one of the modern use-cases for a hub, err, a multi-port Ethernet repeater, here!). The problem arises when you want to scale beyond that. The classic weakness of VRRP as it scales out is the network partition.
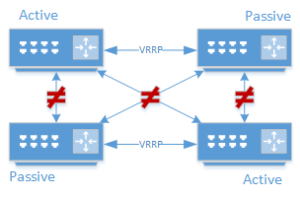
Just to illustrate, I’ve done four participants here. You should see the problem: there’s no inherent concept of quorum – if the multicast domain and links are up, whatever is highest priority grabs the vIP. This means we can have up to N nodes that think they’re master where N is the total number of nodes under the right circumstances.
Now, if this was caused by say a misconfiguration, such that the partition is east/west but traffic continues north/south you’re going to see some bad behavior: TCP retransmits / 50% UDP drops(as CAM tables flip-flop), or a split brain on the services behind the vIP.
There are things you can do in your network design to limit the chances of this happening, but I like to assume that if a horrid state that will utterly fuck me can occur(particularly due to human error), that it is going to occur. Or at least I’m testing for it and kicking it out.
Solution: Using an unreliable participant consensus algorithm to mitigate VRRP network partition vulnerability
Today, those algorithms would be either raft or paxos. We don’t want to have to implement either ourselves (we’d need to call the PHDs for help, particularly with paxos) and there’s almost certain to be a use case for some software that already implements one or the other. In the case of NEU CCIS, we had/have a need for ceph (paxos) and consul (raft). It doesn’t make sense to mitigate transitions on both, so I, basically arbitrarily, chose paxos over raft and thus ceph over consul. A little silly bit of paxos is harder = better than, plus the thought that lots of ceph-mons might be a good idea.
Note: Two links to help go into ceph paxos: Monitors and Paxos: a Chat and the Monitor Config Reference
It’s also really easy to check a ceph-mon service for quorum:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
That’s a very simple chunk of ruby (equally trivial in pretty much everything) that will poll ceph via the admin-daemon socket for quorum status. If ceph isn’t running, it errors (the socket doesn’t exist, triggering an exception). If it is, we error if quorum_status is nil, empty, or if quorum_names fails to include us. Otherwise we exit with a status of 0.
To use this in keepalived is also simple:
1 2 3 4 5 6 7 | |
And this script can then be attached to a VRRP instance via the track_script stanza which causes a loss of ceph quorum to basically invalidate an instance(without a weight, VRRP goes to a FAULT state). Combine with track_interfaces and whatever normal track_scripts you would use to largely mitigate network partitions.
Here’s an example:
1 2 3 4 5 6 7 8 9 10 | |
This obviously only applies to the VRRP portion of keepalived. Keepalived can also integrate with LVS for L3/L4 load-balancing.
So why not use keepalived LVS quorums?
Keepalived when configured for a virtual_server / LVS checks and forms a quorum according to the status of health checks on back-end services. The checks are simple tcp connectivity checks, with other things bolted on over the years. The real problem though is this:
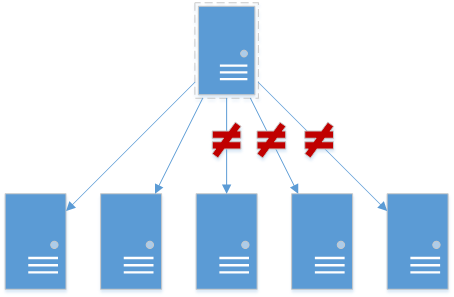
can be a failure state. Sometimes I want this, sometimes I don’t. It also won’t come up or back up into quorum until most of the nodes have done so(I think 4/5, but it depends on some settings).
All of that aside, we also won’t be using LVS. LVS is wicked fast, but we don’t really require wicked fast, and it has some limitations (being L3/L4 and thus application ignorant) that restrict it from use in load balancing some applications. In other words: we don’t really care about the performance hit, so let’s standardize on a higher level load balancer.
Monitoring? Transitions on service failure?
Both haproxy and keepalived can be polled via SNMP. (for keepalived add a -x flag)
For detecting service failure – let your load balancer do the work of determining whether it should serve and to what. Go off the health-check of the LB – trust (yourself to properly configure) haproxy and to define what conditions require a service go offline.
Why haproxy? Why not nginx?
Heritage, mainly. Nginx used to win on http/https proxy balancing at one point (and could be used elsewhere as a web server), but the two are pretty much identical from a performance standpoint today. Haproxy is a proxy load-balancer, and that’s all it does, while nginx is a web server that can also do load-balancing. You have to make decisions on something.
Failure Scenarios
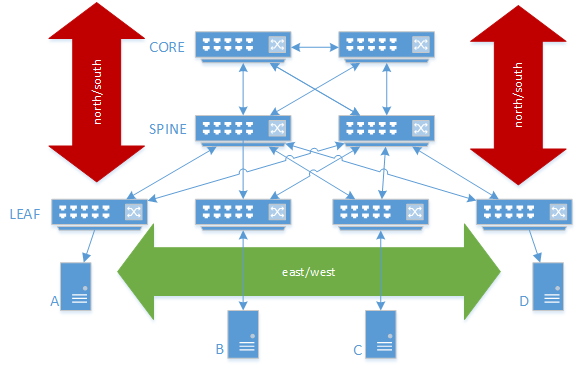
Here’s a not atypical network these days. Leaf/spine topography connected into a core(which probably provides L3). We’re being bad and having 4 servers – A,B,C, and D. I’ve labelled traffic directions in case you aren’t a network engineer. This is pretty damn redundant, so what here are the most likely failure states?
- An individual server dies or loses connectivity
- A leaf dies or loses connectivity
- A misconfiguration causes east-west traffic to partition, a leaf is isolated or leaves split.
Brainstormed with @standalonesa and we’re pretty sure we have these pretty much covered. Anything we missed?