One of the biggest problems with combining continuous integration / continuous delivery with configuration management is dependency resolution. This is because most configuration management is concerned with content, in the form of a desired end state(which may, or may not compose the entirety of the state of the final machine). As the chief concern is content, config management tends to fall into object-oriented design patterns and hierarchical organizational structures.
In a lot of cases, the application stack that needs to be integrated is self-limiting. Core infrastructure services like DNS are provided by third parties(IE: Amazon), development is in house, etc.. As long as the content, or more specifically applications, can dwell on small numbers of nodes(composited or not), the difficulty is limited and the problem is relatively simple. However, as your application and version count grow your classes grow with it and it can quickly become non-viable to have a “fuck it, spin up everything” approach to the world.
Applications
Applications are important. Applications are pretty much all normal people care about, because applications do things. Doing things are what most people who use computers are interested in. I’ll reiterate this because it’s important – Applications do things.
Applications also require things to operate; other applications, libraries, compute resources, memory, storage, a network connection, an ip address, an execution environment, an operating system, version tolerances of everything. A whole web of the verb “requires” surrounds everything forming a specification.
Machines, nodes, containers, are the nouns of the computing world. They’re content. To overuse the pets vs cattle metaphor. A pet may be a proper noun and cattle a noun, but they’re both nouns. Applications are the verbs.
What those verbs operate on, the infrastructure, is defined via one of several ways. It’s the content, a minor novella of facts, actions and adjectives that get a bare metal(or virtual, or container) machine into a necessary state to do the useful work of the application. How we get there today is often via config management, so let’s go into that real quick:
Apache Installation 4 ways
Ansible
---
- hosts: webservers
vars:
http_port: 80
max_clients: 200
remote_user: root
tasks:
- name: ensure apache is at the latest version
yum: pkg=httpd state=latest
- name: write the apache config file
template: src=/srv/httpd.j2 dest=/etc/httpd.conf
notify:
- restart apache
- name: ensure apache is running (and enable it at boot)
service: name=httpd state=started enabled=yes
handlers:
- name: restart apache
service: name=httpd state=restarted
Puppet
package { 'httpd': ensure => latest }
file { '/etc/httpd.conf': ensure => present,
content => ('template/httpd'),
requires => Package['httpd'],
notify => Service['httpd'] }
service { 'httpd': ensure => running, enabled => true }
Chef
package 'apache2'
service 'apache2' do
action [:start, :enable]
end
template '/var/www/html/index.html' do
source 'index.html.erb'
end
Salt
apache:
pkg:
installed
Analysis
You should almost immediately see commonalities here. Each one of these configuration management packages installs apache via the operating system sources, and there are only so many ways to skin a cat. If we were to take the end node and run tests on it, we should see Apache installed, we would likely see it running, and we would almost certainly see content. The mechanisms by which this happen differ, but the result, the content, is largely the same.
This example is also trivial to test, you have one application running on one or more nodes and any changes made to the config can be validated via a single node.
As things expand outward, the idea of classification begins to creep in. I have a lot of machines, and by and large, a lot of them have things in common. Some of these are universal(or per site), ntp settings for example, others start to clump together into classifications. These classifications may be composited (IE: NTP + DNS + TFTP on one node class or server), but to keep things focused on applications we’ll leave them separate.
Classification in a more sophisticated infrastructure

As things grow out, the first division occurs from common between servers and desktops. At the server level a mass diversification quickly occurs. It is within this realm that things quickly become difficult. Classes, metaclasses, roles, we wind up with a hierarchy. Now is this a good thing, or a bad thing? Remember what we care about at this stage is content. And when it comes to content this is a close model of the real world. The closest analog to this is in biology so let’s look there:
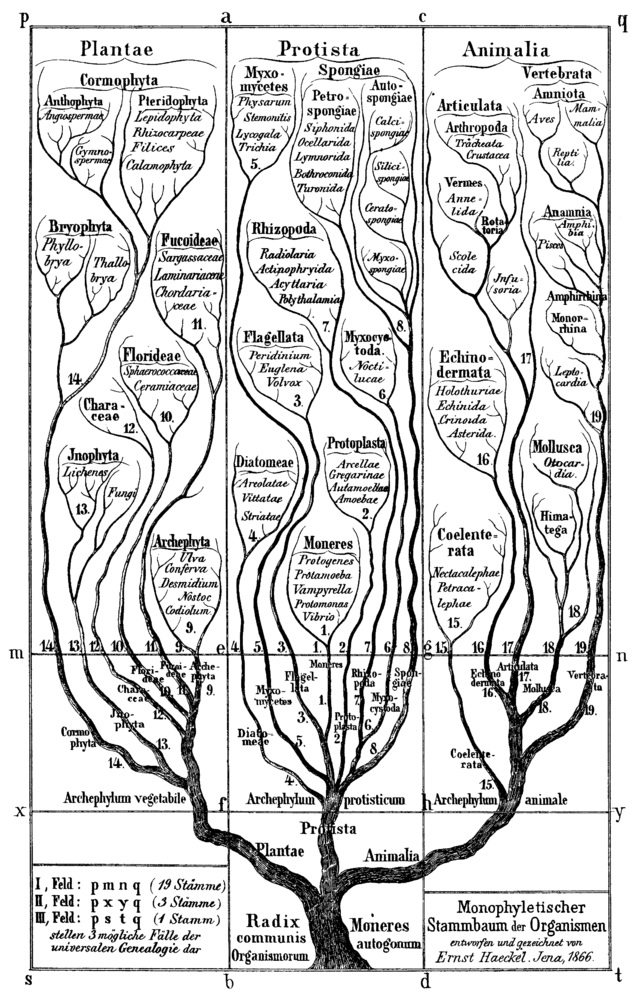
To reiterate, what we have is a hierarchy. Largely unchanged except in details for over a century.
Why does the hierarchy work? Because it defines what things are, the hierarchy provides additional information via the definition of common antecedents. It is defining content. The antecedent is a go here for more information, and the specific extends the antecedent. You know what a lizard is even without knowing the specific species of lizard.
So where is the problem? Content is fact, it is nouns.
Dependencies are verbs in a kingdom of nouns
It’s impossible to reference a kingdom of nouns without pointing to Steve Yegge’s infamous critique of Java.
Because dependencies are driven by applications and applications both do things and require things. Where this matters is testing. As we grow beyond the point where we can model small sets of nodes for our testing we require a higher level of specificity. We simply can’t afford to spin up our entire infrastructure to test things.
Hierarchies tell us things through their antecedents. This is a very limited view into how things actually link and interact.
What really made this click for me was hearing Edward Tufte describe what Tim Berners-Lee was attempting to solve with the semantic web, and this graphic in particular:
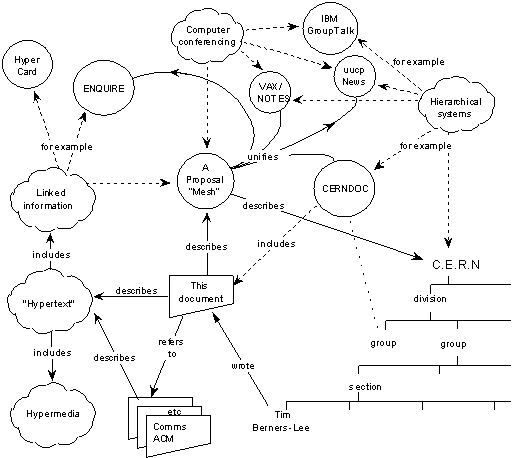
CERN was structuring data similar to how it itself was structured, but the actual data benefited from interlinking, the semantic web. Similarly, modeling where our application links are provides us with great benefit.
Here’s a quick reorganization of the server clado into a web, just for provisioning of virtualization machines:
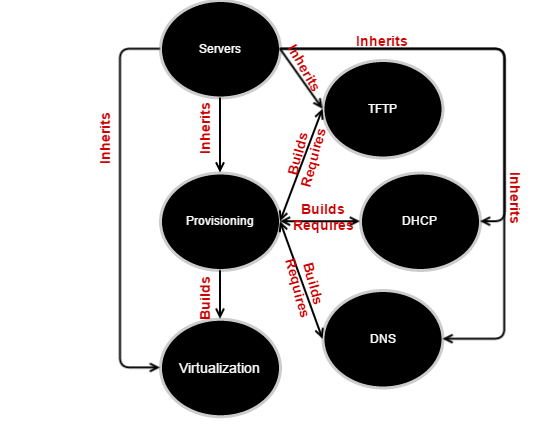
It becomes trivial to determine what impacts what. We can determine what composited canaries or what actual servers should be spun up for testing depending on which components have been messed with. The web captures links between data, but it says nothing about content, so you need both. How, apart from by hand, do you do this?
Service Discovery
Following is a basic diagram of service discovery. The provisioning server gossips that it needs things, other servers gossip that they have things. A match is made. Mazel tov!
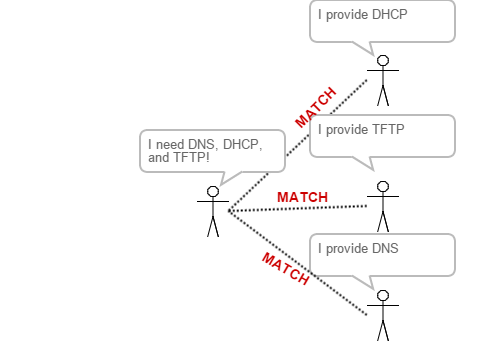
I plan on getting into a lot more detail on service discovery, in particularly consul, at a later date, but in the interim you can read the architecture overview. Think dependency resolution while doing so.
Further Resources
I gave a presentation on this topic in a different way at UCMS ’14 if you aren’t sick of me yet.